Learning Resources
https://www.youtube.com/watch?v=jGwO_UgTS7I&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbUMachine learning is like teaching computers to learn from experience instead of giving them direct instructions it’s one of the most popular parts of AI. Instead of telling the machine every step like do this then do that you show it a bunch of examples and the machine figures out patterns from those examples.
For instance if you want a computer to recognize pictures of cats you don’t write a program explaining what a cat looks like instead you give the machine tons of pictures of cats and not cats and it starts to learn the difference. The more it sees the better it gets at telling what’s a cat and what’s not.
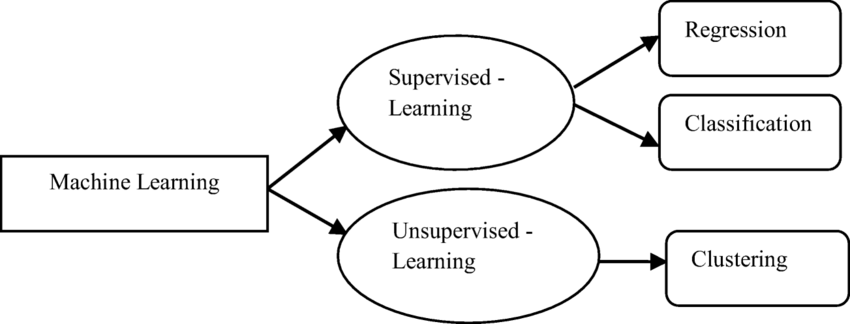
There’s a thing called supervised learning that’s when you give the machine labeled data like telling it “this is a cat” or “this is not a cat” so it knows what to look for. Then there’s unsupervised learning where the machine gets data but no labels and it has to figure out patterns all on its own which can be pretty tricky but also powerful.
Machine learning is used everywhere from recommendation systems like Netflix telling you what to watch next to self-driving cars trying to figure out how to navigate roads without crashing into stuff. It’s also behind voice recognition like when you talk to Siri or Google Assistant.
But it’s not perfect sometimes the machine learns the wrong thing or gets confused especially if the data isn’t good enough. So even though it’s really smart in some ways it still needs a lot of work to make sure it’s learning the right things.
Supervised Learning
Supervised Learning is like teaching a computer how to learn from data it’s all about using labeled data where you have the answers already and you want the model to figure out how to get to those answers on its own you can think of it like a teacher guiding a student the student learns from examples and then tries to answer questions in the future so in supervised learning we have different techniques and two of the main ones are regression and classification they help us solve different kinds of problems.
Regression
first up is regression it’s about predicting continuous values like numbers let’s say you want to know how much a house will sell for based on its size location and other features regression helps you create a model that takes all these factors into account and gives you a price prediction a common type of regression is linear regression it finds a straight line that best fits your data points but sometimes the relationship isn’t just a straight line so you might use polynomial regression that can fit curved lines if the data needs it there are also more advanced techniques like ridge and lasso regression that can help with problems where you have a lot of input features this is important because it prevents something called overfitting where the model learns too much from the noise in the training data and doesn’t perform well on new unseen data so regression is great for estimating values.
Classification
classification which is different because it’s about sorting things into categories for example imagine you want to figure out if an email is spam or not you’d use classification to train a model based on labeled examples of spam and not spam emails then the model learns the patterns and can classify new emails as spam or not spam so it’s about making decisions like yes or no or assigning a category think of it like sorting laundry into colors and whites classification algorithms can be simple like logistic regression or more complex like decision trees and random forests each has its own way of making decisions based on the input features.
Ensemble Methods
ensemble methods which combine multiple models to make better predictions think of it as a group of friends discussing a decision each one has their own opinion and together they come up with a better answer ensemble methods like bagging and boosting take several models and combine their strengths bagging involves training multiple models on different subsets of the data and then averaging their predictions this helps reduce variance and makes the model more stable boosting on the other hand focuses on improving the mistakes of previous models so it trains them sequentially giving more weight to the ones that got it wrong it’s like learning from your mistakes to get better.
in supervised learning you choose the right technique based on your problem if you want to predict numbers you go with regression if you need to classify things you pick classification and if you want to improve accuracy by combining models you use ensemble methods they all have their own unique roles in the machine learning world and together they help create more accurate and reliable models this is how supervised learning works it’s like having different tools in a toolbox each one for a specific job and knowing which one to use makes all the difference in solving problems with data.
Un Supervised Learning
unsupervised learning is like letting a computer figure things out on its own without any labels or answers given it’s all about finding patterns in data when we don’t have the right answers upfront we can use unsupervised learning to explore the data and understand it better two main techniques in this area are clustering and dimensionality reduction these help us make sense of complex datasets
Clustering
clustering it’s all about grouping similar things together for example imagine you have a bunch of different fruits and you want to sort them into categories like apples bananas and oranges without telling the computer what each fruit is clustering helps with that so k-means is one popular method it works by choosing a set number of clusters say three for our three fruit types then it picks random points in the data as the cluster centers these points are like the heart of each group the algorithm then assigns each fruit to the closest cluster based on its features like color size and shape after all fruits are grouped it recalculates the centers and keeps adjusting until the clusters don’t change much anymore it’s like refining a recipe until it tastes just right
another clustering method is hierarchical clustering which builds a tree-like structure of clusters this method can be really useful when you want to see how data groups at different levels you start by treating each data point as its own cluster then you combine them based on similarity until you get one big cluster it’s kind of like making a family tree where you see how people are related to each other this way you can visualize how the data is organized and see if there are subgroups within your clusters so clustering is super handy for exploring data and finding natural groupings without needing to know the answers
Dimensionality Reduction
dimensionality reduction this technique is all about simplifying data by reducing the number of features or dimensions while keeping the important information it’s like trying to fit a big puzzle into a smaller box without losing the picture one popular method for dimensionality reduction is principal component analysis or PCA it takes a dataset and finds the directions where the data varies the most it then projects the data onto these new axes which helps in reducing the number of dimensions while still preserving most of the variation so if you have a dataset with lots of features like colors sizes and shapes PCA helps you reduce it to just a few that capture the essence of the data
then there’s t-SNE which stands for t-distributed stochastic neighbor embedding this one is more focused on visualizing high-dimensional data it takes complex data and transforms it into two or three dimensions so we can plot it on a graph it’s great for seeing how different points in the data relate to each other and can help uncover hidden patterns t-SNE is often used in fields like biology to visualize data from experiments so you can see how different samples cluster together
in summary unsupervised learning is about letting the computer find patterns in data without any guidance it helps us group similar things through clustering like k-means and hierarchical clustering and it simplifies complex data with dimensionality reduction techniques like PCA and t-SNE these methods help us understand our data better and reveal insights that we might not have seen before it’s like exploring a new place without a map discovering connections and relationships along the way which can be super exciting and useful in many fields like marketing finance and science.
Semi Supervised Learning
semi supervised learning is kind of a mix between supervised and unsupervised learning it’s like having a teacher and also doing some self-study at the same time in this approach you use a small amount of labeled data and a large amount of unlabeled data to train your machine learning model so imagine you have a dataset where only a few examples have the correct answers like maybe only a few pictures of cats and dogs are labeled but you have tons of pictures that are not labeled semi-supervised learning helps to make use of all that extra unlabeled data which is really helpful because getting labeled data can be expensive and time consuming.
the cool thing about semi-supervised learning is that it leverages the patterns and structure in the unlabeled data to improve learning so it starts with the small labeled set and trains the model then it uses the model to predict labels for the unlabeled data this way it gets to see what the model thinks about the rest of the data then the model can refine itself by learning from both the labeled and the predicted labels it’s kind of like a feedback loop where the model keeps getting better over time.
a popular technique used in semi-supervised learning is called self-training in this method the model is initially trained on the labeled data and then it predicts labels for the unlabeled data the most confident predictions are added to the training set and the model is retrained with this expanded set this process can go on for several rounds this helps the model learn better because it gets more data to work with even if some of the added labels are not completely accurate.
another approach is co-training where you use multiple models to label the data each model is trained on different features of the data they help each other by labeling the unlabeled data then they get combined to make a stronger overall model so it’s like having different perspectives and using them to improve the final result.
semi-supervised learning is really useful in situations where you have limited labeled data but lots of unlabeled data it can be applied in various areas like image recognition text classification and even medical diagnoses where getting labeled data is hard but there is plenty of unlabeled information available so this approach helps to make better models while saving time and resources it’s a smart way to use the data we have to its fullest potential.
Ensemble Methods
Ensemble methods are a cool way of improving machine learning models by combining several smaller models instead of relying on just one model. Imagine you’re trying to make a decision and you ask a bunch of friends for their opinions instead of just one friend. Each friend might have a different perspective, and when you put all their opinions together, you might get a better overall decision. That’s what ensemble methods do in machine learning.
There are different ways to create these ensembles like bagging and boosting. Bagging is when you take several models and train them separately on different random samples of the data then you average their predictions or take a majority vote if it's a classification problem. Random forest is a popular example of bagging where many decision trees work together to improve accuracy and reduce overfitting which means avoiding making mistakes because the model got too focused on noise in the data.
Boosting is another technique where models are trained one after another and each new model tries to fix the mistakes made by the previous ones. It's like if each time you asked a friend for advice they tried to correct what the last friend got wrong instead of starting from scratch. One popular boosting method is called XGBoost which is used a lot because it tends to perform really well on many problems.
The idea is that by combining these weaker models we can get something stronger and more accurate overall but it does come with a cost since it usually takes more computing power and time to train an ensemble compared to a single model
Important Note
If there are any mistakes or other feedback, please contact us to help improve it.