Learning Resources
https://www.youtube.com/watch?v=PySo_6S4ZAg&list=PLoROMvodv4rOABXSygHTsbvUz4G_YQhObDeep learning is kind of like machine learning but on a much bigger level it’s about using a bunch of layers in something called neural networks to help computers learn really complicated things. You can think of it like how the brain works in layers but it’s not exactly the same it just tries to mimic that idea. The more layers it has the “deeper” it goes that’s why it’s called deep learning.
For example if you wanted a computer to recognize faces deep learning would look at different things like first the edges of the face then maybe the eyes or the nose and then put it all together to say yeah that’s a face. It’s really good at doing tasks like recognizing images or understanding speech that’s why it’s used in things like facial recognition or self-driving cars where it needs to understand complex stuff.
One of the most common types of deep learning is something called a convolutional neural network (CNN) that’s used for image data like helping the computer see and figure out what’s in a picture. Another kind is called recurrent neural networks (RNNs) which are used for tasks involving time or sequences like language translation.
Deep learning is powerful because it can handle a huge amount of data but it also needs a lot of computing power and time to train these models. So it’s not always easy to get it right sometimes it makes mistakes or overthinks things because the more layers it has the more complicated it gets
Neural Networks
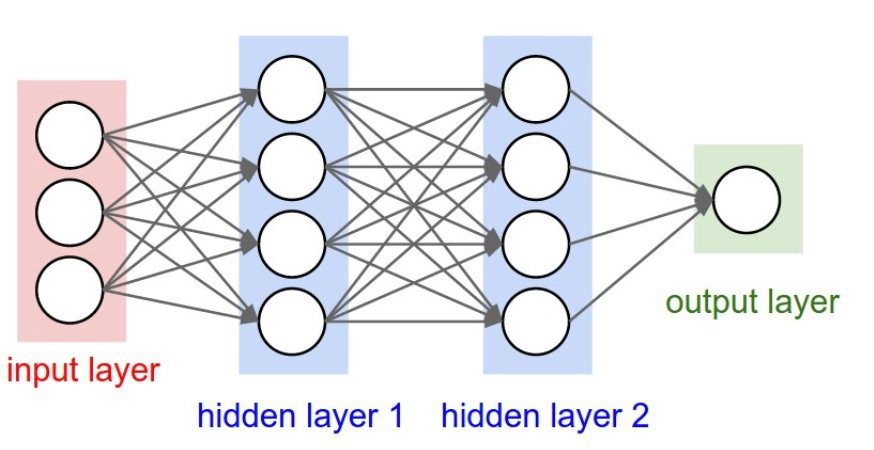
Neural networks are like the brains of AI systems they try to mimic how the human brain works by having lots of connections and layers to process information so imagine neurons in the brain each neuron gets signals from other neurons and decides whether to pass the signal forward or not that's kind of how neural networks work in machine learning.
Feedforward Neural Networks (FNNs) Feedforward Neural Networks (FNNs) which are the most basic type here data moves in one direction from the input layer to the output layer there’s no going back no loops or anything that’s why they are called feedforward because the data only goes forward each layer of neurons processes the data and sends the results to the next layer until the final output is given for example if you’re trying to classify whether an image is a cat or a dog the image would go through the different layers of the FNN and at the end the network will give you a result like 90% cat or 10% dog but even though FNNs are simple they have limitations they can’t handle tasks where time or sequence matters like predicting the next word in a sentence because they don’t have any memory.
Convolutional Neural Networks (CNNs) Convolutional Neural Networks (CNNs) which are mostly used for image recognition unlike FNNs that treat every pixel in an image equally CNNs look at different parts of the image and try to capture features like edges textures and shapes CNNs use something called filters or kernels that scan over the image in small parts so for example if you have a photo of a dog the CNN might detect its eyes nose ears and body separately and then put it all together at the end to identify the dog one of the reasons CNNs work so well for images is that they reduce the number of parameters by sharing weights between neurons across the image this makes them more efficient than FNNs when dealing with large images.
Recurrent Neural Networks (RNNs) Recurrent Neural Networks (RNNs) now RNNs are special because they have a sort of memory they’re good at processing sequences of data like text or time series data where the order of the data matters unlike FNNs RNNs allow information to loop back so what they’ve learned at one step can be used in the next step if you're using an RNN to predict the next word in a sentence the network remembers the previous words and uses that information to predict what comes next but RNNs have a problem they can forget important information over time especially when working with long sequences this is called the vanishing gradient problem it means that as the network goes back in time its memory of earlier information fades which can make it hard to learn long-term patterns.
Long Short-Term Memory Networks (LSTMs) LSTMs are a type of RNN but with a special architecture that allows them to remember information for longer periods they have something called gates that control how information flows in and out of the network so instead of just forgetting everything from the past like normal RNNs LSTMs decide whether to keep or discard information from earlier steps if you’re using an LSTM to generate text it can remember important details from earlier in the sentence like who or what is being talked about which helps it make more accurate predictions LSTMs are great for tasks like speech recognition language translation and even time-series forecasting because they’re able to handle long dependencies in the data. All of these types of neural networks have their strengths and weaknesses FNNs are simple but they can’t handle sequences CNNs are amazing for images because they reduce the complexity of analyzing an entire picture all at once RNNs are great when the order of the data matters but they struggle with long sequences LSTMs take it a step further by being able to hold onto important information for much longer periods. Each type of neural network is designed to solve different kinds of problems and as AI continues to develop we might see new types of networks being developed too but for now FNNs CNNs RNNs and LSTMs are some of the most important and widely used.
Generative Models
Generative models are pretty interesting because instead of just recognizing things like most machine learning models they can actually create new stuff so they can generate new data like images text or sounds based on what they’ve learned from existing data two popular types of generative models are Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs).
Variational Autoencoders (VAEs) GANs they are a bit like a game between two players you have two neural networks one is called the generator and the other is called the discriminator the generator tries to create fake data like an image of a cat and the discriminator’s job is to look at that image and decide if it’s real or fake so it’s like a battle the generator keeps getting better at faking images and the discriminator gets better at spotting the fakes the goal is for the generator to get so good that the discriminator can’t tell the difference between real and fake images GANs are famous for creating super realistic images and even deepfakes.
Variational Autoencoders (VAEs) Variational Autoencoders (VAEs) are a bit different they try to learn the underlying structure of the data by encoding it into a simpler form and then decoding it back to something close to the original so for example if you feed a VAE lots of images it will try to figure out the patterns in those images and then create new ones based on those patterns but the cool thing about VAEs is that they add a bit of randomness which helps them generate more diverse and interesting results they aren’t as flashy as GANs but they are easier to train and useful for tasks where you want to explore the different variations in your data like creating new types of faces or artwork.
Transfer Learning
Transfer learning is kind of like when you already learned something and use that knowledge to learn something new faster instead of starting from scratch so in machine learning it works the same way instead of training a model from the beginning which can take a lot of time and data you start with a model that's already been trained on something similar.
Imagine you’ve trained a model to recognize cats and now you want to train it to recognize dogs instead of training a whole new model you take the cat model and just tweak it a bit to recognize dogs because cats and dogs share some features like fur and four legs the model already has a lot of useful info that can be reused.
This method is super helpful especially when you don’t have a ton of data or computational power because you're building on top of something that already works it's commonly used in deep learning with large models like those used in image recognition or natural language processing for example you can take a model trained on millions of images and fine-tune it to recognize specific objects in a smaller dataset you save time resources and get good results without starting from zero.
Training Deep Networks
Training deep networks is a process that involves teaching a neural network how to make better predictions over time it's like training your brain by doing exercises again and again but for computers so in deep learning you have a network of layers with each layer containing neurons which are like tiny decision-makers the goal is to adjust the weights between these neurons so the network learns to make accurate predictions for the task at hand like classifying images or predicting numbers.
Backpropagation
is one of the key methods used during training it's the way the network learns from its mistakes after the network makes a prediction the result is compared to the actual answer using a function called a loss function this loss tells the network how wrong it was so in backpropagation the error is sent backward through the network adjusting the weights of each neuron layer by layer this adjustment is done in the opposite direction of how the data flowed forward during prediction hence the name backpropagation it’s like when you realize you made a mistake and retrace your steps to figure out where things went wrong.
Activation Functions are also super important in deep networks without them the network wouldn't be able to learn complex things they take the weighted sum of inputs from the previous layer and decide whether a neuron should be activated or not like turning on or off a switch different activation functions have different behaviors
ReLU short for Rectified Linear Unit is the most common activation function it’s simple if the input is positive it passes it through but if it’s negative it just outputs zero this is super helpful because it keeps things efficient and prevents the network from getting stuck in complicated calculations.
Then there's the Sigmoid function it's like an “S”-shaped curve which squashes the inputs between 0 and 1 this was used more in earlier neural networks because it’s great for making predictions that need probabilities but it's not as common now because it can slow down learning a bit it makes the network learn in small steps.
To make sure the network is adjusting its weights in the best possible way we use something called optimizers these optimizers tweak the weights so the network learns faster and better over time two popular ones are Adam and SGD.
SGD stands for Stochastic Gradient Descent which is an older method it works by taking small steps in the direction that reduces the error after each prediction however it can be slow sometimes because it doesn't always find the best path to the right answer.
Adam which stands for Adaptive Moment Estimation is more advanced it’s like SGD but with some tweaks that make it more efficient and faster Adam keeps track of past gradients which helps the network make better updates to the weights it’s like learning from past mistakes so you can adjust more wisely the optimizer is crucial in making sure the network gets smarter and faster over time without them training deep networks would take forever and might never even learn properly.
So overall the process of training deep networks involves these three big concepts backpropagation helps the network learn from its mistakes activation functions decide when a neuron should be active and optimizers like Adam and SGD help guide the learning process faster and more efficiently without these elements deep networks wouldn't work as well or learn complex patterns the way they do.
Applications of Deep Learning
Deep learning has become super popular because it’s being used in so many cool areas right now one of the most common applications is image recognition which is all about teaching computers to look at pictures and figure out what’s in them it’s used everywhere from your smartphone recognizing faces to social media tagging friends in photos deep learning is really good at this because it can learn patterns and details in images that are too complicated for traditional methods to figure out
Image Recognition
image recognition work in deep learning it uses special types of neural networks called convolutional neural networks or CNNs these networks are great at handling images because they can pick out patterns like edges shapes and textures in a picture then they combine these patterns to recognize objects so if you show a CNN a picture of a cat it will first look for features like fur whiskers and ears then it puts these together to decide that the picture is a cat over time the network gets better and better at this because it learns from thousands or even millions of examples
Speech Recognition
speech recognition which is all about teaching machines to understand human speech so that when you talk to your phone or a smart speaker like Alexa it can actually understand what you’re saying this is a bit trickier than image recognition because speech is not just about recognizing words it’s also about understanding accents tone and context deep learning makes this possible by using recurrent neural networks or RNNs which are great at handling sequences of data like the sound waves in speech
RNNs are special because they can remember what came before in a sequence this means that if you're saying a long sentence the network can keep track of the words you said earlier which helps it understand the next words for example if you say “the dog is running” the RNN will remember that you already mentioned “dog” so it expects something like an action word next like “running” instead of some random word deep learning for speech recognition has gotten so good that it’s used in things like voice assistants transcription services and even translating languages in real-time.
Another big area where deep learning is making a difference is natural language processing or NLP this is the field where machines learn to understand human language so that they can process it analyze it and even generate it you can see NLP in action in things like chatbots machine translation and even sentiment analysis where a machine figures out if a piece of text is positive or negative.
For NLP deep learning uses a type of neural network called transformers these are super powerful because they can understand context way better than older methods so let’s say you’re typing something into Google Translate a transformer network can figure out not just the words you typed but also the context of the whole sentence to give a much better translation than old-school systems this is because transformers are really good at handling big chunks of text and they can figure out the relationships between all the words much more effectively
One of the biggest breakthroughs in NLP thanks to deep learning has been in machine translation where computers can now translate languages with much more accuracy than before this is done by training the deep learning models on huge amounts of text in different languages then the models learn how words and sentences should be structured in each language so when you type a sentence in English it can figure out how to translate it into French Spanish or any other language
Chatbots are another area where NLP is being used more and more with deep learning chatbots can now hold conversations that feel much more natural instead of just responding to simple commands they can actually understand more complex requests and give better answers this is really useful in customer service where chatbots are being used to answer questions and help people solve problems without needing a human to step in
Natural Language Processing
So to sum it all up deep learning is having a huge impact on areas like image recognition speech recognition and natural language processing in image recognition deep learning models like CNNs are being used to recognize objects in photos and videos speech recognition uses RNNs to understand spoken words and translate them into text or commands and in natural language processing deep learning models like transformers are helping machines understand and generate human language making things like chatbots and translation much smarter all of these applications show how deep learning is changing the way computers interact with the world around them and making technology a lot more useful in everyday life.
Deep Learning Frameworks
Deep learning frameworks are basically the tools that make it easier to build and train deep learning models without needing to write everything from scratch one of the most popular frameworks out there is TensorFlow it was developed by Google and has been around for a while TensorFlow is great because it’s super flexible and can handle pretty much anything you throw at it you can use it for big projects or even smaller ones and it works really well with a variety of hardware so you can run it on your computer or even on big servers with lots of GPUs. TensorFlow TensorFlow has this thing called tensors which are just multi-dimensional arrays that hold the data you’re working with the whole framework is built around these tensors and the operations you perform on them and what’s cool is that you can define the structure of your neural network using these tensors then TensorFlow will automatically figure out how to run everything as efficiently as possible it even handles things like automatic differentiation which is a fancy way of saying it calculates all the gradients you need to update your model during training without you having to worry about the math behind it. One of the other reasons TensorFlow is so popular is that it has a lot of pre-built models and tools that make it easier to get started you don’t always have to build your neural networks from scratch because there are libraries like TensorFlow Hub that give you access to models that have already been trained on large datasets so if you’re working on something like image classification or natural language processing you can just use one of these pre-trained models and fine-tune it for your specific task this saves a ton of time and makes TensorFlow a good choice for both beginners and experts PyTorch Another deep learning framework that’s really popular is PyTorch it was developed by Facebook and it’s known for being really easy to use compared to some of the other frameworks PyTorch has become the go-to framework for a lot of researchers because it feels more natural to write code in it PyTorch uses dynamic computation graphs which means that the graph is created on the fly as you run the code this makes it easier to debug and experiment with because you can see exactly what’s happening at each step of your model training. One of the best things about PyTorch is that it’s very Pythonic which means it feels like writing regular Python code you don’t have to deal with a lot of extra complexity and it’s really straightforward to build and train models you can just define your neural network as a class and PyTorch handles the rest and just like TensorFlow it also has built-in support for things like automatic differentiation so you don’t have to worry about the complex math PyTorch also has a strong community of users which means there are a lot of resources out there like tutorials and pre-built models that you can use to learn or get started quickly. PyTorch has also been widely adopted in academia because of how easy it is to prototype and experiment with new ideas if you’re doing research and want to try out a new type of neural network PyTorch makes it really easy to test things out and see results quickly a lot of research papers and new advancements in deep learning are now using PyTorch for this reason it’s also great for working with datasets because of its tight integration with Python libraries like NumPy so if you’re already comfortable with Python PyTorch will feel very natural. Both TensorFlow and PyTorch are really powerful but they also have some differences that make them better suited for different types of projects TensorFlow is often used in production environments where you need to deploy large-scale models that can run efficiently on servers or mobile devices TensorFlow Lite is a version of TensorFlow that’s optimized for running models on smartphones and other edge devices this makes it a great choice if you’re building apps that need to use machine learning on the go/ PyTorch on the other hand is often preferred for research and experimentation because of how easy it is to prototype and iterate on new ideas its dynamic graph structure makes it more flexible for certain types of projects and many researchers prefer it for this reason however in recent years PyTorch has also started to be used more in production as well especially with the introduction of tools like TorchServe which makes it easier to deploy PyTorch models at scale. In conclusion both TensorFlow and PyTorch are amazing deep learning frameworks that help you build and train neural networks without needing to write all the code from scratch TensorFlow is super flexible and great for deploying models at scale while PyTorch is more user-friendly and popular among researchers and people who want to experiment with new ideas depending on what kind of project you’re working on and what your goals are you might choose one over the other or even use both in different parts of your workflow.
Important Note
If there are any mistakes or other feedback, please contact us to help improve it.